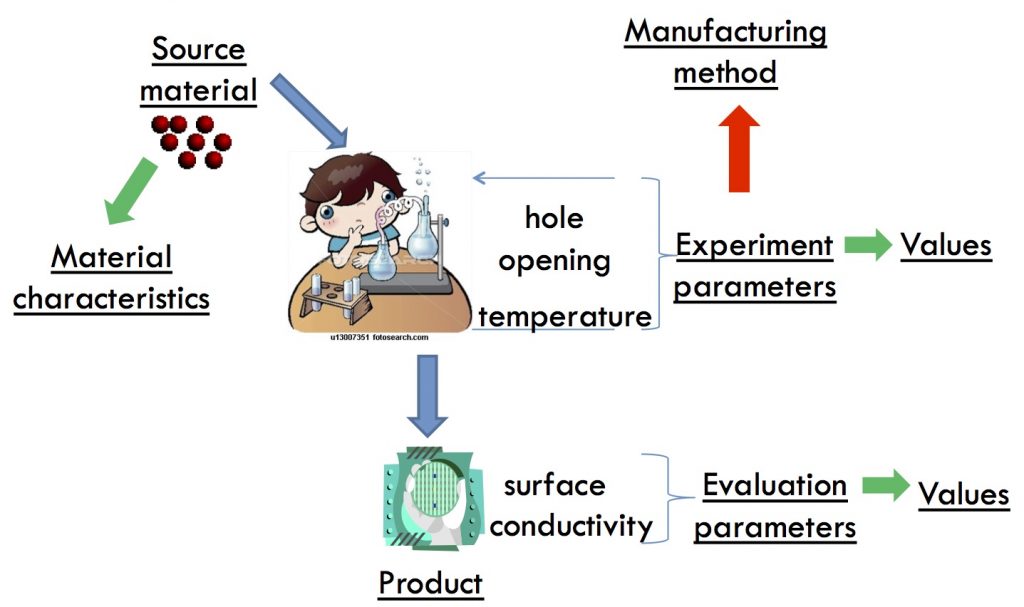
In order to understand the different parameter settings for same layer construction, it is better to understand the background information about the experiment such as purpose, evaluation criteria, and so on.
In the experiment record sheet, there is a slot for describing purpose of the experiment. However, there is not sufficient information about the manufacturing devices. So we decide to extract information related to the experiment from the research paper. Our approach is to construct an annotated corpus to extract the necessary information from those related research papers.
The tagged corpus approach has several advantages. First of all the extracted information can be used in different nanoscale research domains. Also this information can be used to find similarity metrics between existed experiments and a planned one. In addition to that, a well defined general corpus will be a good collaboration schema among researchers in nanodevice, computer science and natural language processing, and help accelerating the process of dealing with problems in the field of nanoinformatics, like to use it for automatic annotation, same as tagged corpus construction in bioinformatics (e.g., GENIA project).
We conduct interviews with nanodevice researchers, based on these discussions, we propose a candidate tag set for annotating the
research papers as follows.
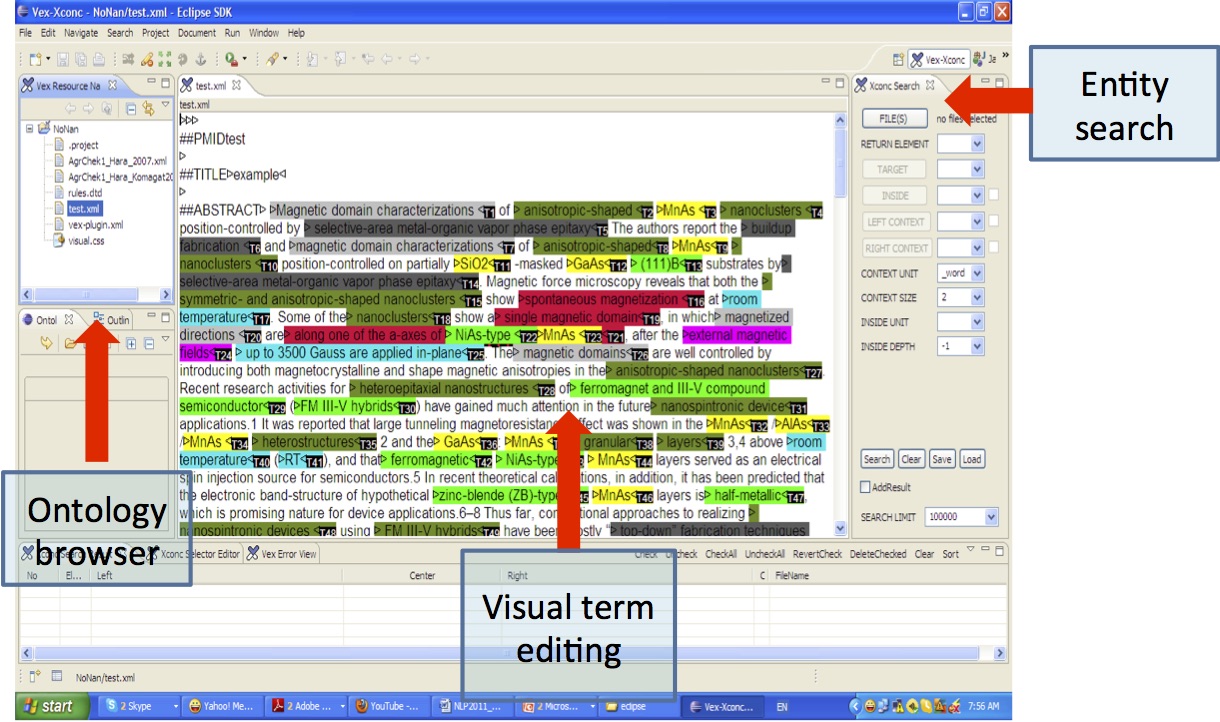
Followings are example of the annotated corpus.
- Thaer M. Dieb, Masaharu Yoshioka, and Shinjiro Hara: NaDev: An Annotated Corpus to Support Information Extraction from Research Papers on Nanocrystal Devices. Journal of Information Processing, Vol. 24, No. 3, pp. 554-564, 2016.
- Thaer M. Dieb, Masaharu Yoshioka, Shinjiro Hara, and Marcus C. Newton :
Framework for automatic information extraction from research papers on nanocrystal devices. Beilstein Journal of Nanotechnology,
Vol. 6, pp. 1872-1882, 2015.